Адреса компании:
Санкт-Петербург
196158, Санкт-Петербург,
Пулковское шоссе, д. 30,
корп. 4, Лит. А, офис 203
Тел: +7 812 414 95 41
Москва
129085, г. Москва, проезд Ольминского, д. 3а, стр. 3, офис 706
Тел: +7 495 616 00 53
Блог
26.08.2015
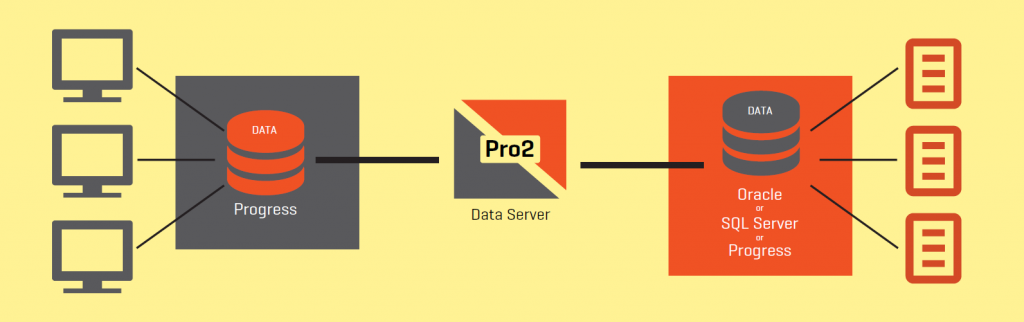
Progress OpenEdge: промышленные средства репликации данных в Oracle и MS-SQL


![]()
![]()
![]()
![]()
")